CGINF - Coordenação Geral de Informações Gerenciais
DIGID - Diretoria de Governança e Inteligência de dados
Data de Publicação
17 de abril de 2025
Resumo
Este tutorial aborda o cálculo e a visualização do Índice de Gini, uma medida estatística amplamente utilizada para avaliar a desigualdade na distribuição de renda em populações ou regiões.
1 Introdução
A desigualdade salarial entre os servidores públicos federais é um tema relevante para o debate sobre justiça distributiva e eficiência na gestão pública. Este relatório analisa a distribuição dos rendimentos utilizando o Índice de Gini, uma métrica amplamente utilizada para avaliar desigualdade de renda.
O Índice de Gini permite medir a dispersão dos rendimentos dentro do funcionalismo, possibilitando uma análise mais detalhada da concentração salarial entre diferentes órgãos e carreiras. Compreender esse indicador é essencial para subsidiar políticas de gestão de pessoal e avaliar o impacto das estruturas salariais na administração pública.
Essa métrica fornece um valor numérico que varia de 0 a 1, onde 0 representa igualdade perfeita (todas as pessoas possuem a mesma renda) e 1 representa desigualdade máxima (uma única pessoa detém toda a renda, enquanto as demais não possuem nenhuma) (Hoffmann 2006).
Ao calcular o Índice de Gini para a remuneração dos servidores públicos, é possível obter uma compreensão clara da distribuição salarial no setor público federal. Esse índice é frequentemente utilizado por economistas, pesquisadores e gestores para medir e comparar a desigualdade entre órgãos, carreiras e ao longo do tempo. A partir dessa análise, é possível identificar padrões de concentração salarial e avaliar o impacto de políticas de reajuste, progressão e reestruturação de carreiras.
Dentre os aspectos analisáveis com o Índice de Gini na remuneração dos servidores públicos federais, destacam-se:
Disparidades salariais entre diferentes órgãos e carreiras;
Impacto de políticas de valorização profissional na redução da desigualdade;
Efeitos da progressividade ou regressividade dos planos de carreira;
Comparação da desigualdade salarial ao longo do tempo e em diferentes períodos de ajuste fiscal.
2 Cálculo do Índice de Gini
O Índice de Gini é calculado da seguinte maneira:
\[
G = \frac{\sum_{i=1}^{n} \sum_{j=1}^{n} |x_i - x_j|}{2n^2 \bar{x}}
\]
Onde:
- ( G ) é o Índice de Gini.
- ( n ) é o número de observações na amostra.
- ( x_i ) são os valores ordenados da variável de renda.
- ( x_j ) são os valores ordenados da mesma variável de renda.
- ( || ) representa o valor absoluto.
- ( {x} ) é a média da variável de renda.
3 Análise dos Dados
Para ilustrar a aplicação do Índice de Gini na remuneração dos servidores públicos federais, utilizaremos dados do Sistema Integrado de Administração de Pessoal (SIAPE). Esses dados contêm informações sobre a remuneração de servidores do Poder Executivo Federal.
Código
# carregar a base de dados em excel e compilar todas as abas em um único arquivo# Carregando as bibliotecas necessáriaslibrary(readxl)library(dplyr)library(purrr)library(tidyr)library(ggplot2)library(ggtext)library(ggdist)library(glue)library(patchwork)library(camcorder)library(gt)library(ggstatsplot)library(plotly)#gg_record(dir = "tidytuesday-temp", device = "png", width = 10, height = 8, units = "in", dpi = 320)# Define o caminho do arquivofile_path <-"data/BaseDados_EstudoDesigualdades.xlsx"# Obtém os nomes de todas as abas no Excelsheet_names <-excel_sheets(file_path)# excluir abas que não serão utilizadas # aba FORA sheet_names <- sheet_names[!sheet_names %in%c("FORA")]# Lê todas as abas e combina em uma única base usando purrr::mapBaseDados_Unica <- sheet_names %>%map_df(~read_excel(file_path, sheet = .x) %>%mutate(sheet_name = .x)) # Adiciona o nome da aba como coluna (opcional)# preencher valores NA na coluna escolaridade_cargo com "Não Informado"# filtrar apenas campos que possuem servidoresdf_gini <- BaseDados_Unica |> janitor::clean_names() |>replace_na(list(escolaridade_cargo ="Sem informação")) |>rename( "2026"= ano_2026, "2023"= mai_23 ) |>pivot_longer(`2023`:`2026`, names_to ="Ano", values_to ="remun") |>filter(qtd >0) df_gini %>% DT::datatable(rownames =FALSE, filter ="top",options =list(pageLength =5, scrollX =TRUE)) %>% DT::formatStyle(columns =names(df_gini), target ="row",lineHeight ="12px", # Reduz a altura das linhasfontSize ="12px"# Reduz o tamanho da fonte )
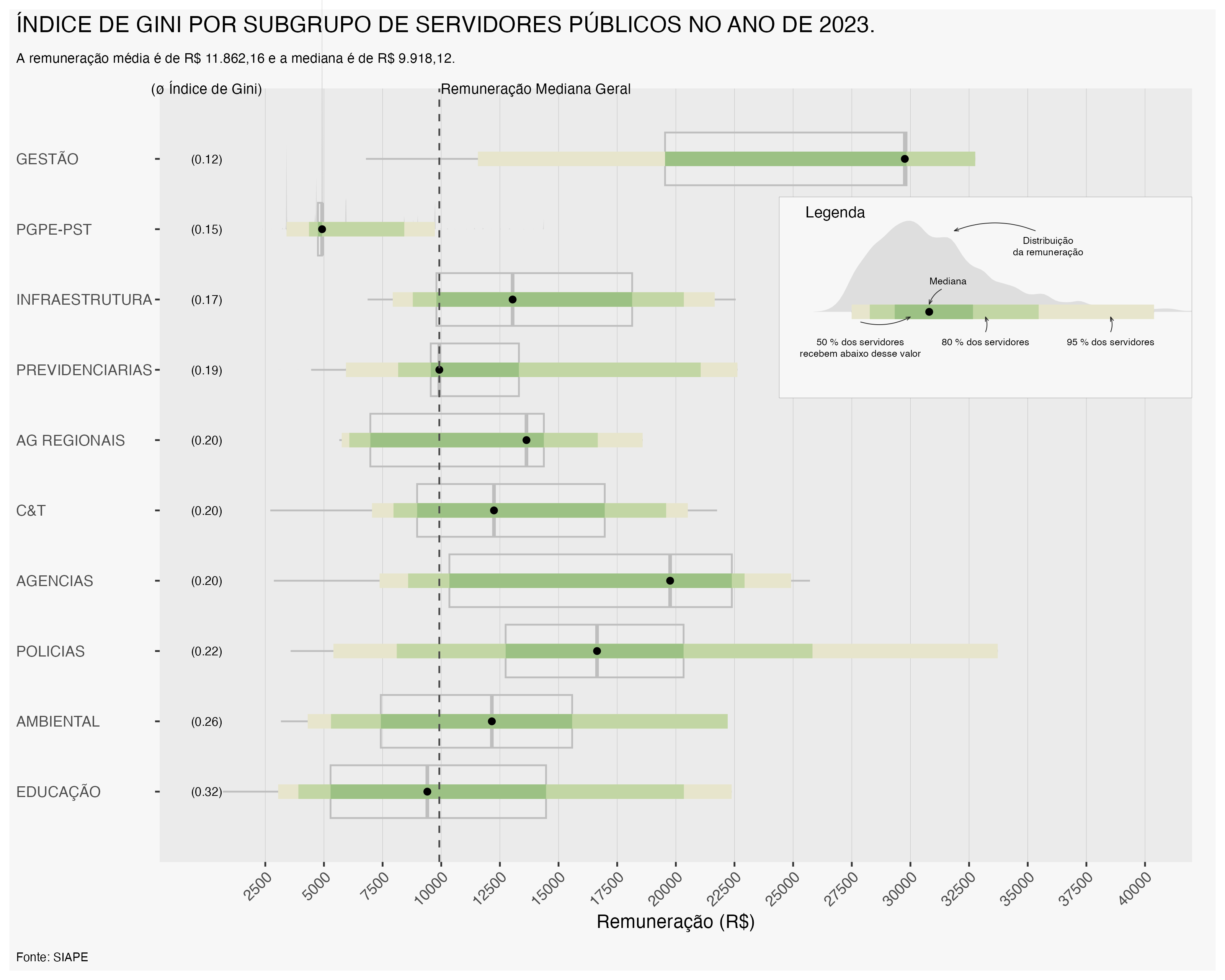
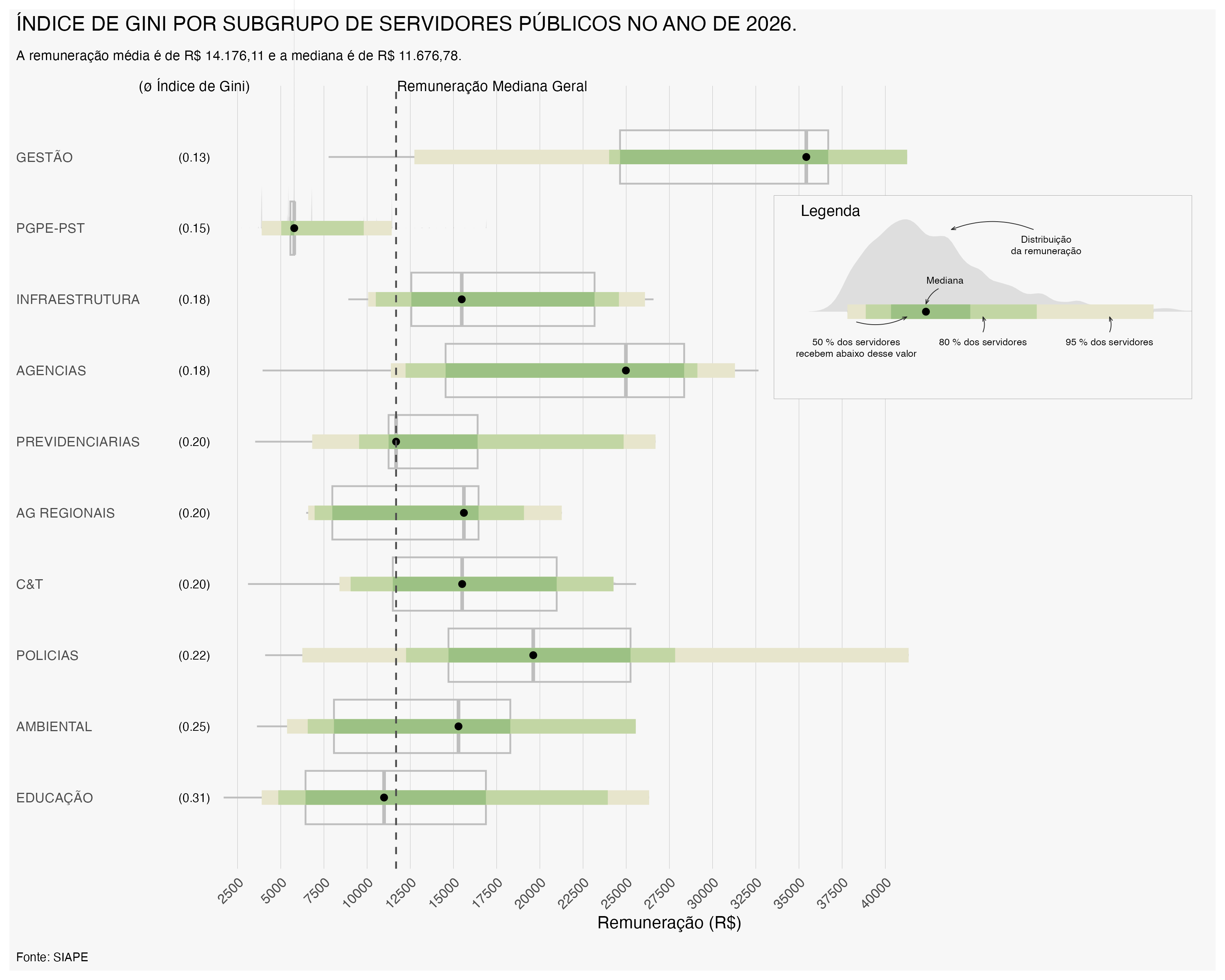
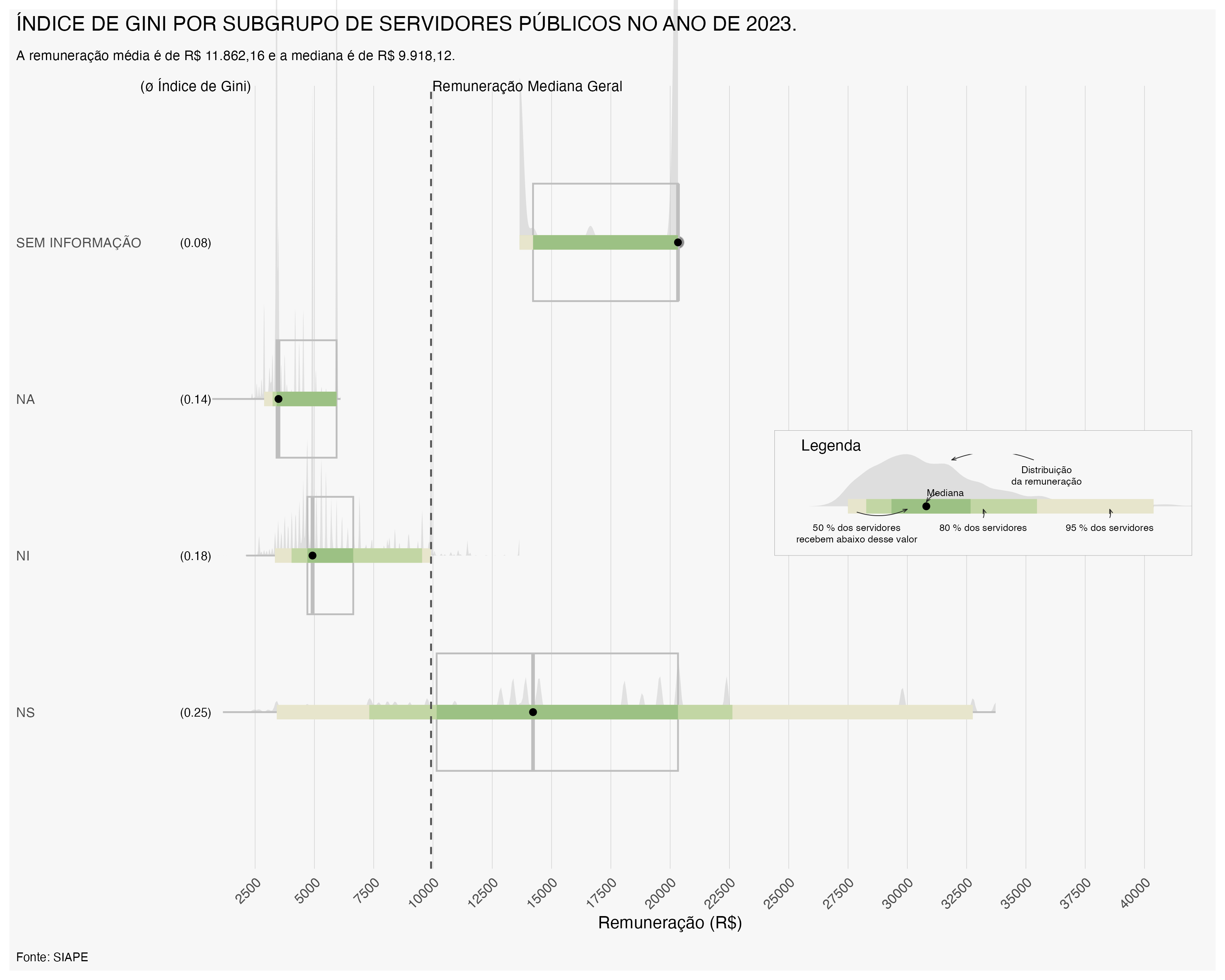
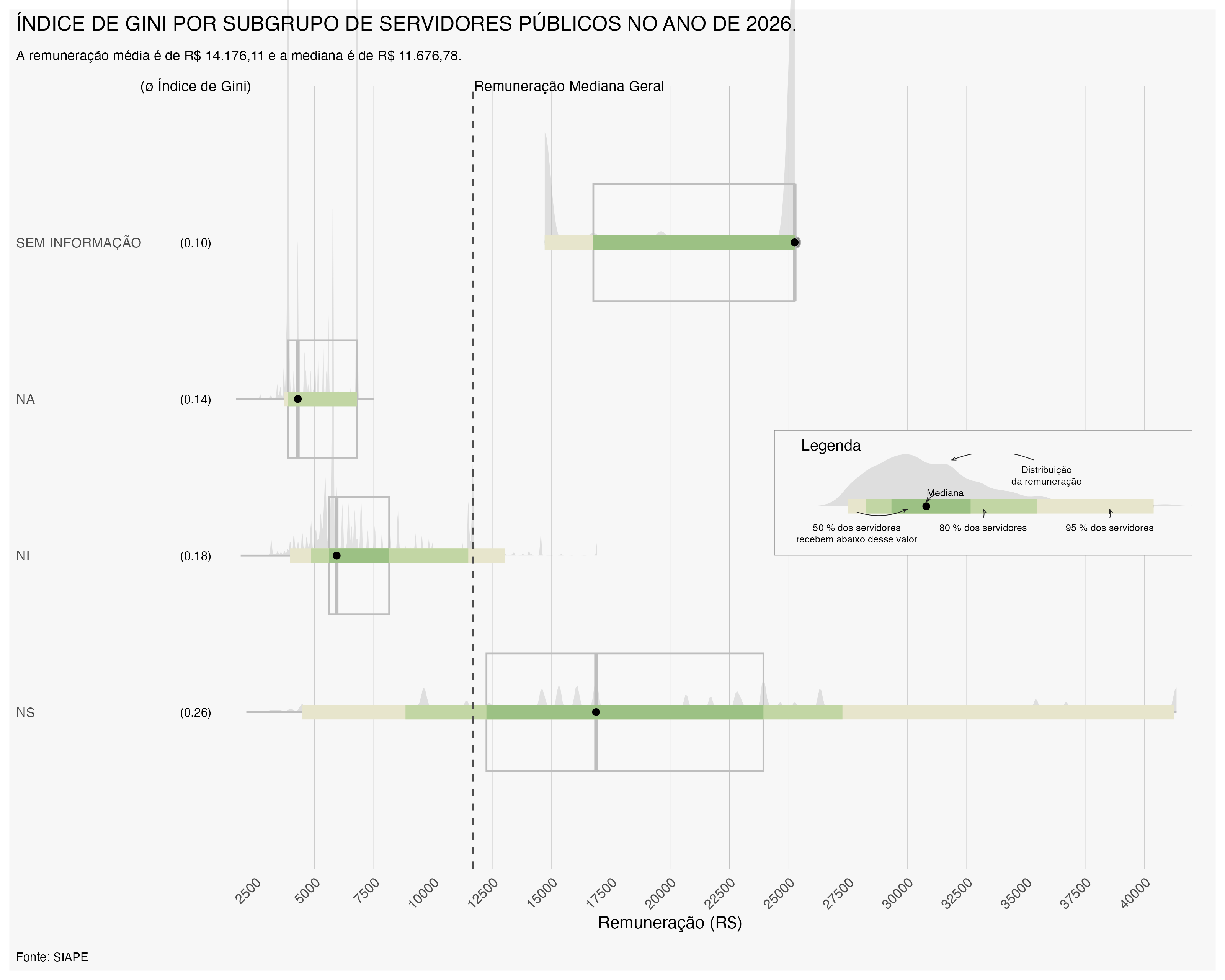
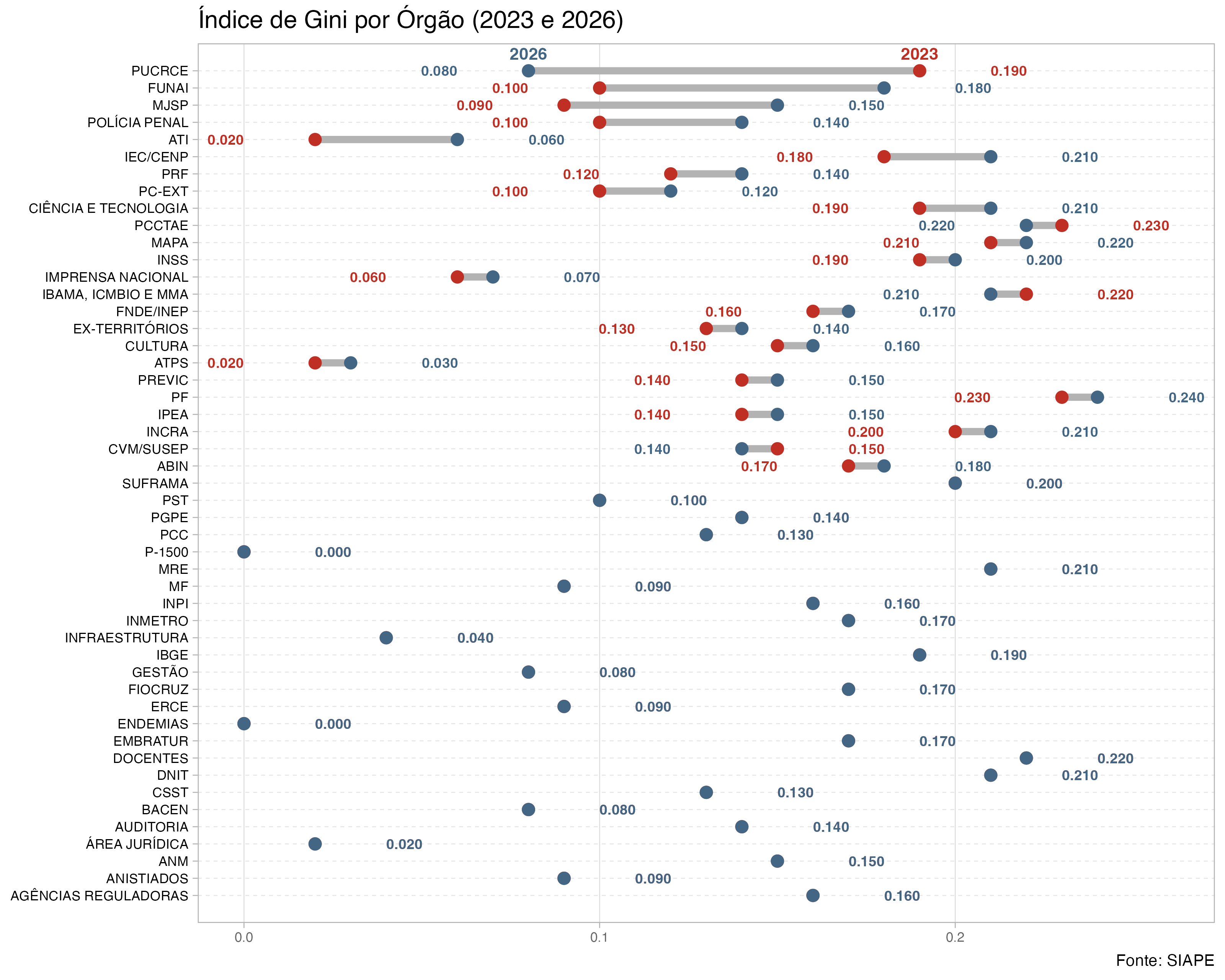
O Índice de Gini também pode ser calculado para diferentes órgãos do Poder Executivo Federal, permitindo uma análise mais detalhada da desigualdade salarial entre instituições. A seguir, apresentamos um gráfico demostrando a evolução do Índice de Gini por órgão no ano de 2023 e 2026.
Observa-se que em 2026, em azul, o Índice de Gini apresentou uma redução em relação a 2023, em vermelho, para a maioria dos órgãos. Nos casos em que o Índice de Gini não apresentou redução, o gráfico apresenta apenas o indice em 2026
Código
# Expandir a base de dados com base na quantidade de observaçõesdf_expandido <- df_gini %>%uncount(qtd)# Calculo do indice de gini por anodf_gini_orgao <- df_expandido |>#filter(Ano == "2023") |> group_by(orgao_area, Ano) |>summarise(total_remun =sum(remun, na.rm =TRUE),gini_index =ifelse(total_remun >0, reldist::gini(remun), NA) ) |>select(-total_remun) |>ungroup() |>mutate(gini_index =round(gini_index, 2))# pivotar wide df_gini_orgao_wide <- df_gini_orgao |>pivot_wider(names_from = Ano, values_from = gini_index) |>mutate(gap =`2023`-`2026`) |>group_by(orgao_area) |>mutate(max=max(`2023`, `2026`)) |>ungroup() # Reordenando a variável orgao_area com base no gap em ordem decrescentedf_long_i <- df_gini_orgao_wide |>arrange(desc(abs(gap))) |>mutate(labels=forcats::fct_reorder(orgao_area , abs(gap))) |>ungroup()df_long <- df_long_i %>%select(-c(orgao_area))%>%pivot_longer(`2023`:`2026`, names_to ="name", values_to ="value") library(forcats)library(scales)nudge_value =0.2p_main <- df_long %>%ggplot(aes(x = value, y = labels)) +# Linhas entre os pontosgeom_line(aes(group = labels), color ="gray70", linewidth =2) +# Pontos com cores personalizadasgeom_point(aes(color = name), size =3) +# Rótulos para os valoresgeom_text(aes(label =label_number(accuracy =0.001)(value), color = name),size =3,fontface ="bold",nudge_x =if_else(df_long$value == df_long$max, 0.02, -0.02),hjust =if_else(df_long$value == df_long$max, 0, 1)) +# Adicionando legenda personalizada ao lado direito do gráficogeom_text(aes(label = name, color = name),data = df_long %>%filter(gap ==max(gap)),nudge_y =1,fontface ="bold",size =3.5) +# Estilizando tematheme_light(base_size =12) +theme(legend.position ="none",axis.text.y =element_text(color ="black", size =8),axis.text.x =element_text(color ="#666666", size =8),axis.title =element_blank(),panel.grid.major.y =element_line(color ="gray90", linetype ="dashed"),panel.grid.minor =element_blank()) +# Título e legendaslabs(title ="Índice de Gini por Órgão (2023 e 2026)",caption ="Fonte: SIAPE", ) +# Ajustando coresscale_color_manual(values =c("#BF2F24", "#436685")) +# Ajustando limites do gráficocoord_cartesian(ylim =c(0, 50)) knitr::include_graphics("tidytuesday-temp/2025_02_03_14_45_21.663065.png")
set.seed(123)p <-ggdotplotstats(data = df_long |>filter(name =="2023"),y = labels,x = value,test.value =55,type ="robust",title ="Indice de Gini por Órgão",xlab ="Indice de Gini",ylab ="Órgão",group = name, # Diferencia os anos por corggtheme =theme_minimal(8)) ggplotly(p)
Código
set.seed(123)p <-ggdotplotstats(data = df_long |>filter(name =="2026"),y = labels,x = value,test.value =55,type ="robust",title ="Indice de Gini por Órgão",xlab ="Indice de Gini",ylab ="Órgão",group = name, # Diferencia os anos por corggtheme =theme_minimal(8)) ggplotly(p)
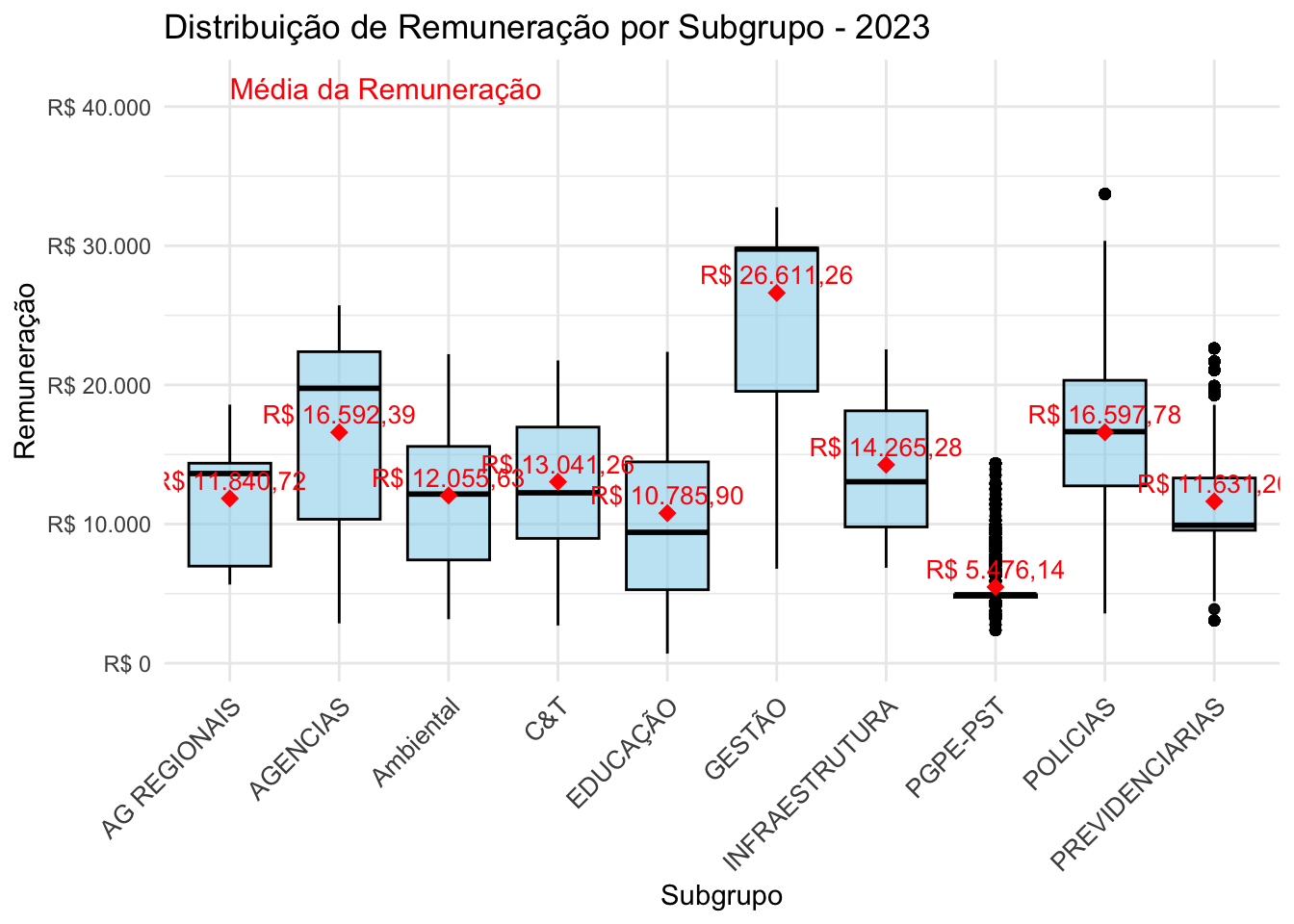
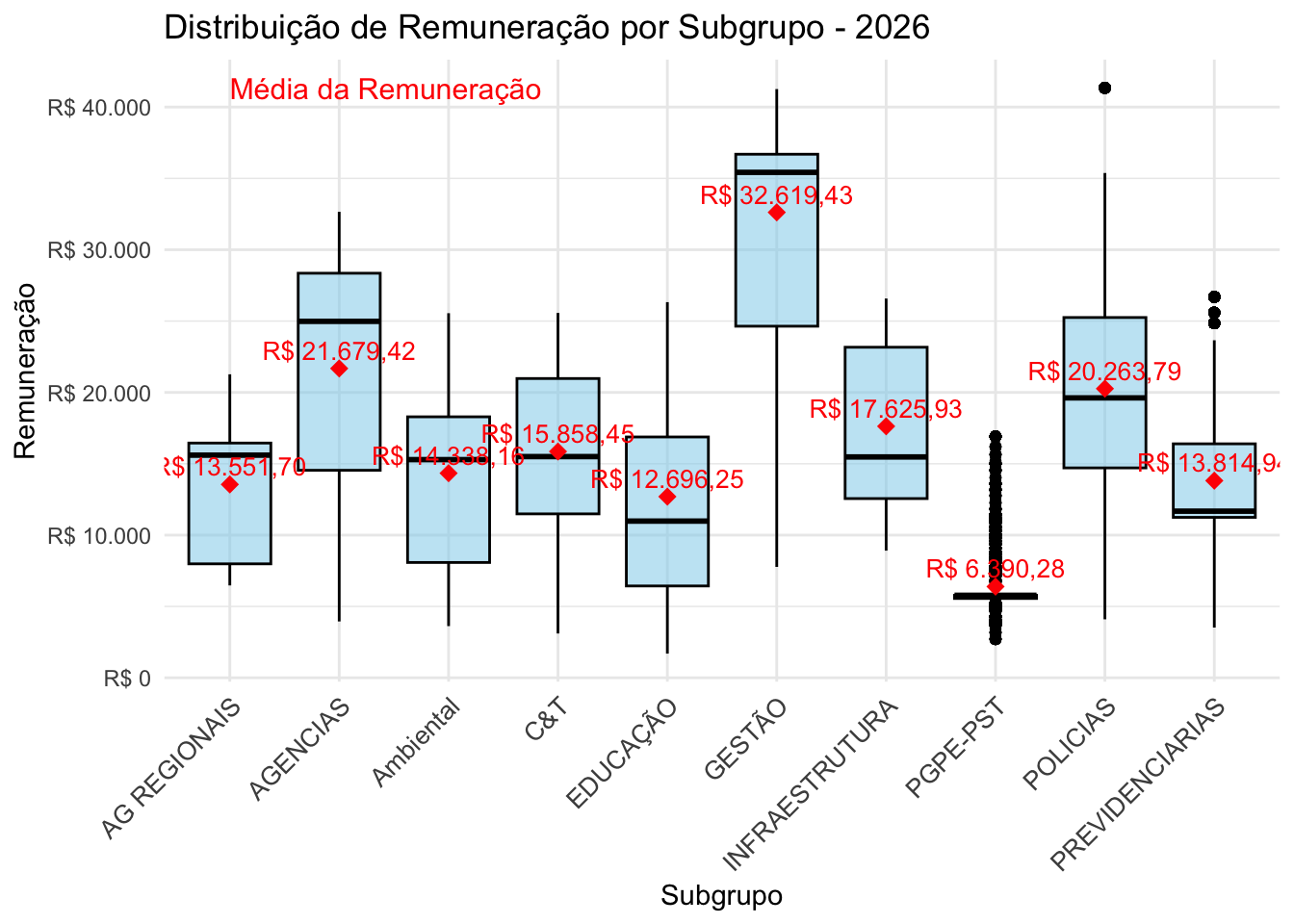
4 Estatísticas descritivas da remuneração dos servidores públicos federais
Código
library(plotly)library(ggplot2)# Gráfico de barras para 'subgrupo', separado por 'ano'p1 <-ggplot(df_expandido, aes(x = subgrupo)) +geom_bar(fill ="steelblue") +theme_minimal() +labs(title ="Distribuição por Subgrupo ", x ="Subgrupo", y ="Contagem") #facet_wrap(~ Ano) # Separa os gráficos por anoggplotly(p1) # Transforma em um gráfico interativo
5 Descritivas por ano
Código
library(gtsummary)library(dplyr)# Criar tabelas separadas para cada anotabela_2023 <- df_expandido %>%filter(Ano =="2023") %>%select(subgrupo, remun) %>%tbl_summary(by = subgrupo) # modify_caption("**Ano 2023**")tabela_2026 <- df_expandido %>%filter(Ano =="2026") %>%select(subgrupo, remun) %>%tbl_summary(by = subgrupo)# modify_caption("**Ano 2026**")# Empilhar as tabelas verticalmentetabela_empilhada <-tbl_stack(list(tabela_2023, tabela_2026),group_header =c("Ano 2023", "Ano 2026") # Adiciona título para cada tabela)# Exibir a tabela empilhadatabela_empilhada
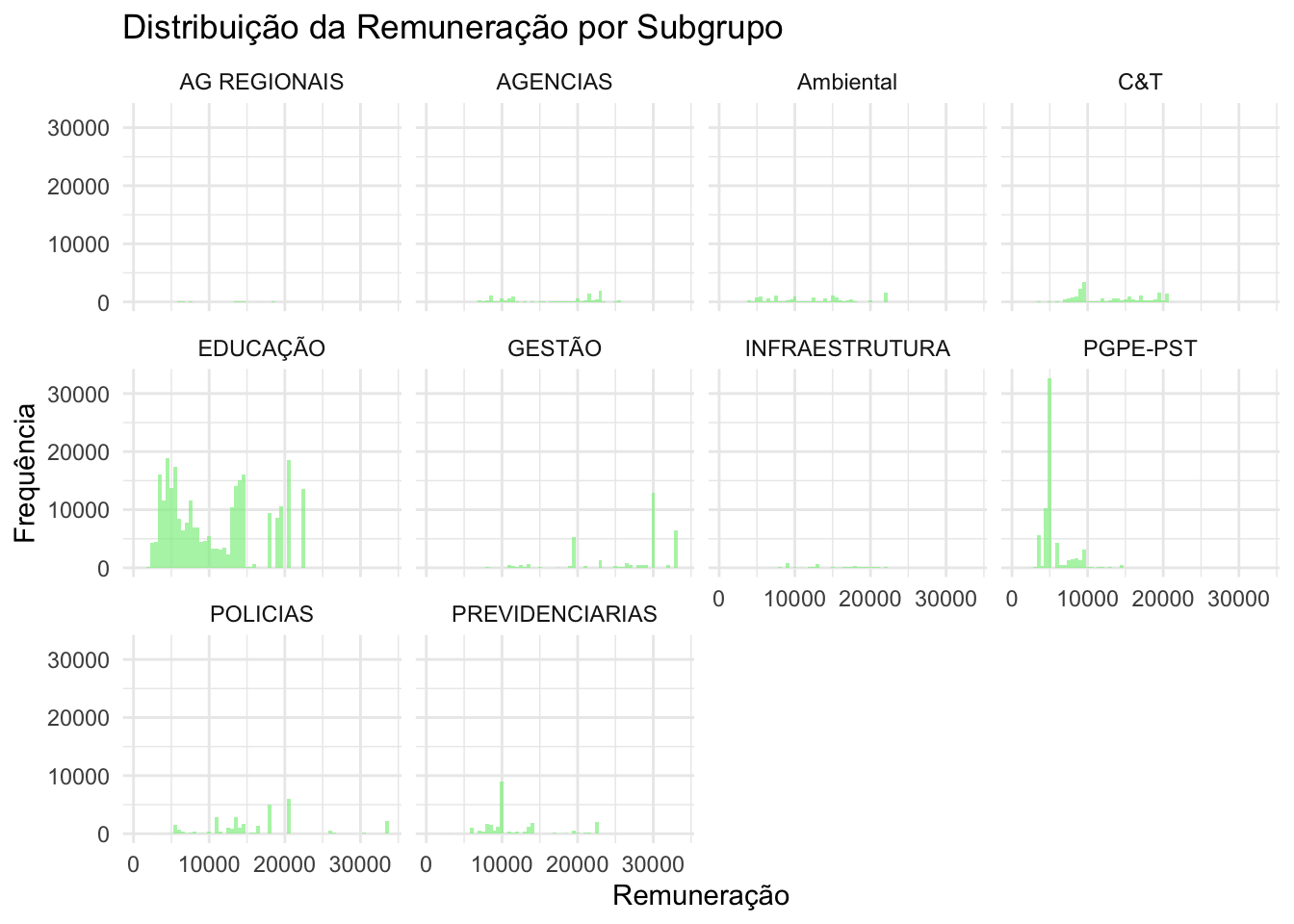
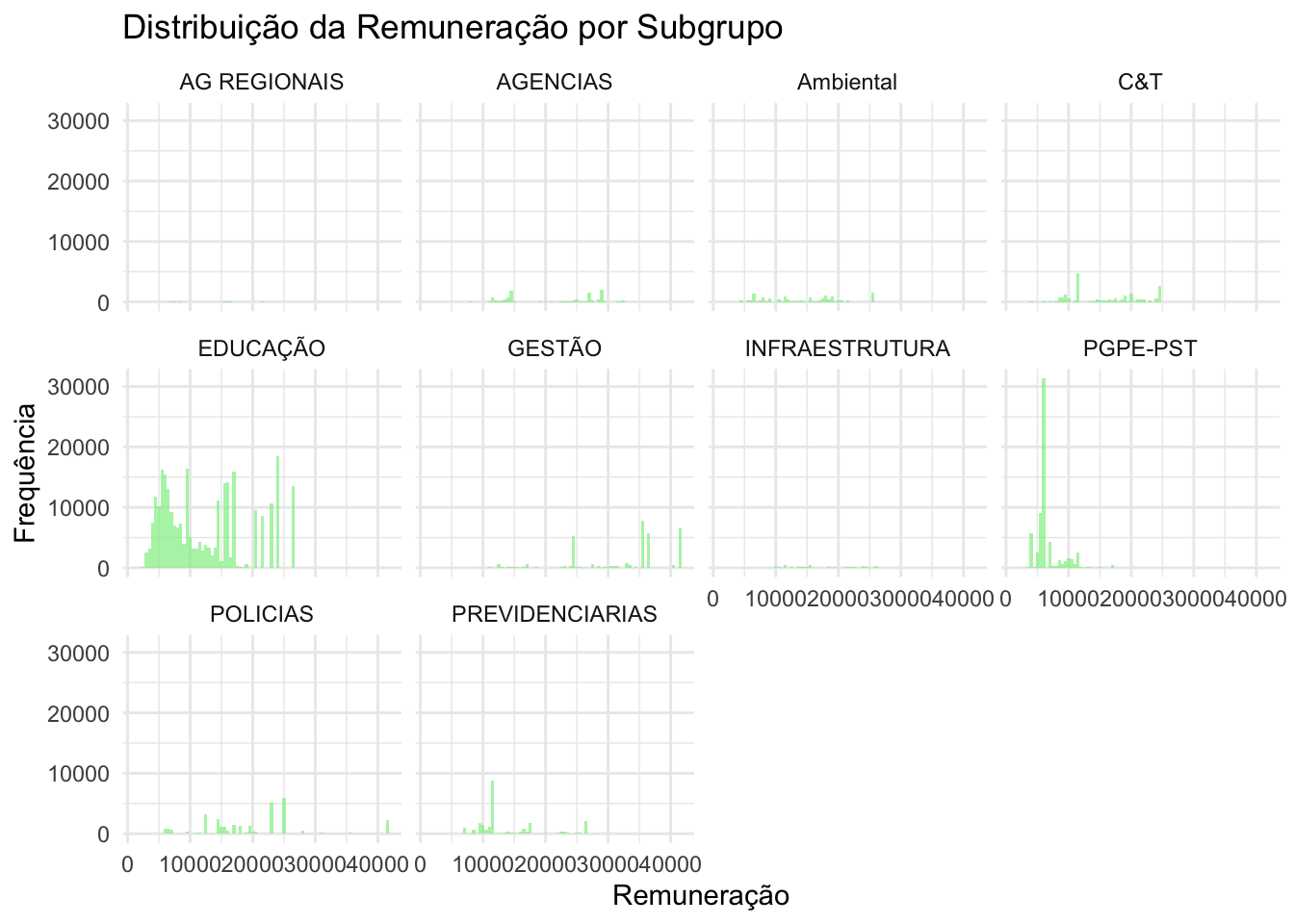
ggplot(df_expandido |>filter(Ano =="2023"), aes(x = remun)) +geom_histogram(binwidth =500, fill ="lightgreen", alpha =0.7) +facet_wrap(~subgrupo) +# Facetando por subgrupolabs(title ="Distribuição da Remuneração por Subgrupo",x ="Remuneração",y ="Frequência" ) +theme_minimal()
2026
Código
ggplot(df_expandido |>filter(Ano =="2026"), aes(x = remun)) +geom_histogram(binwidth =500, fill ="lightgreen", alpha =0.7) +facet_wrap(~subgrupo) +# Facetando por subgrupolabs(title ="Distribuição da Remuneração por Subgrupo",x ="Remuneração",y ="Frequência" ) +theme_minimal()
8 Comparação de médias entre grupos
2023
Código
# df_expandido |> filter(Ano == "2023") |> ggstatsplot::ggbetweenstats(# x = subgrupo,# y = remun,# title = "Distribuição de Remuneração por Subgrupo (2023)"# )
2026
Código
# df_expandido |> filter(Ano == "2026") |> ggstatsplot::ggbetweenstats(# x = subgrupo,# y = remun,# title = "Distribuição de Remuneração por Subgrupo (2023)"# )
9 Referências
Hoffmann, Rodolfo. 2006. Estatística para economistas. 1.ª ed. Cengage Learning.